
1. Find accessibility issues
Google Webmaster Tools is the best place to search for any accessibility issues your website may have. This free software can help you understand what is going on with your website.
A partner to Google Analytics, Webmaster Tools is more focused on the technical parts of your website.
Google discovers your site’s content by spending out what is known as a ‘spider’ to crawl your site. This bot goes around from link to link, cataloguing and/or indexing what it finds. When the spider attempts to look at a page, your server will return a HTTP status code in response. This code provides the Google spider with key information about your page.
Once you are logged into your Webmaster Tools account you can check to see if Google’s spider has found any errors on your website. For example, it may find a ‘404 error’ which means ‘page not found’. The message will be displayed like so:
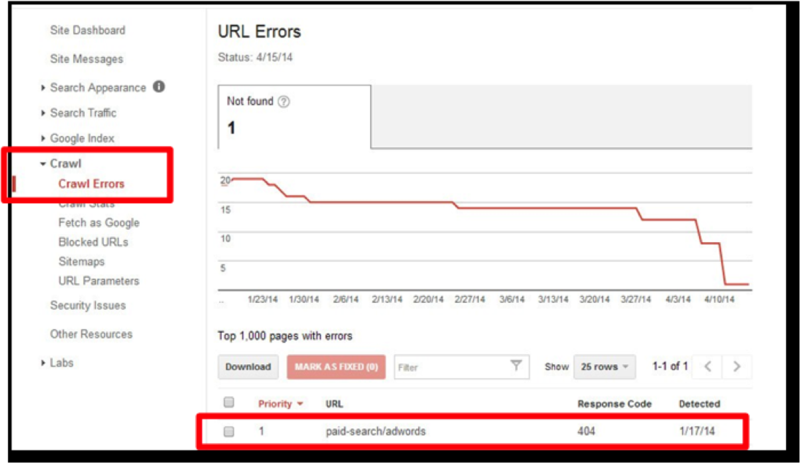
2. Simplify the URL structure
Having a good site structure will improve your chance of ranking well in Google’s results. By making the URL structure clear and simply will allow search engines to easily find your most important content as well as helping your users to enjoy a great user experience.
We recommend using a structure that is similar to that below – all the important content being within two clicks of the homepage where possible.
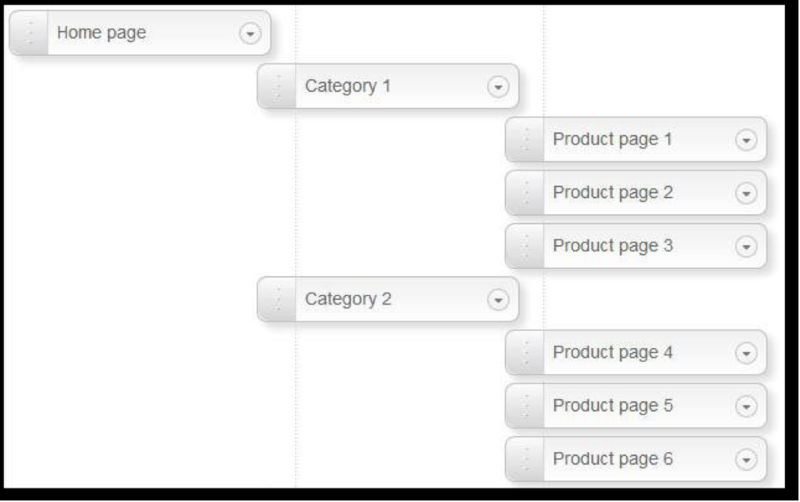
Your users will likely assume that your most important content is close to your homepage, as will search engines. In the example below, product A is likely to attract more traffic than product B:
www.example.com/category/product-A
www.example.com/category/sub-category/ sub-sub-category/product-B
3. Create an XML sitemap
Another way to let Google know which pages you consider important is by creating an XML sitemap.
An XML sitemap is a text file that maps your site and makes sure search engines crawl and index the pages on your website efficiently.
Your sitemap can also communicate other useful information to Google – such as which pages you consider to be the most important and which have been changed recently.
4. Check your robots.txt file
A common method of communicating with Google’s spider is to use a Robots.txt file.
This is a text file that allows you to tell search engines which of your site’s pages you want to crawl and which not to index. If your site already has this file, it’s often found at yoursite.com/robots.txt
Here is an example of what your robots file may say:
User-agent: *
Disallow: /
The “Disallow: /” line tells the spider not to crawl the site. In practice this means you’re instructing Google not to include any of your pages to be indexed in their search results.
5. Identify duplicate content
Duplicate content is a very common SEO issue.
Google may not show your pages in its results if it finds multiple versions of a page. This means your site is likely to suffer.
A common example of duplicate content is like so:
www.yoursite.com www.YOURSITE.com
You may think these are one of the same but this is not necessarily the case. Google could see each version as a separate page. This would likely cause a problem with your rankings.
Other common duplication examples are as follows:
i. Architecture
Duplicate content is common on ecommerce sites. This problem commonly occurs when a product on the site is placed into more than one category with the site’s architecture not correctly setup to accommodate this properly.
Below is an example of a ‘whiskey tasting kit’ on yourgiftsite.com being incorporated into multiple categories. This allows the product to be accessed via a number of paths through the site:
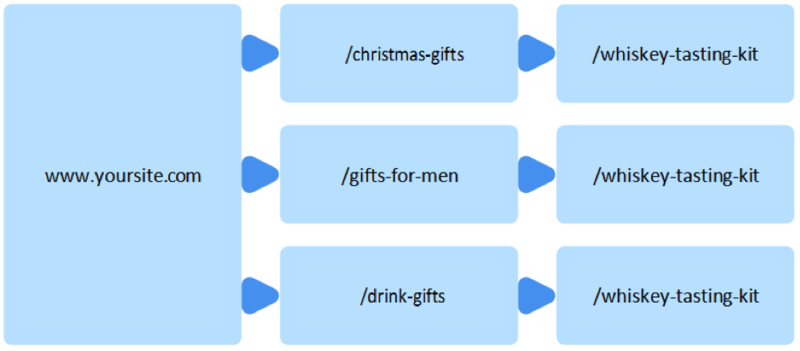
Although this may make sense to a user, from a search engine’s point of view it is classed as duplication.
ii. HTTP vs HTTPs
HTTPs session can also cause duplicate content. HTTPs pages are secure, often for logins, shopping baskets and payment transactions – they provide an encrypted connection, making them more secure than a HTTP page.
Below is an example of how to tell when you’re on a secured page:

If a page is accessible via both HTTP and HTTPs this may cause duplication issues.
iii. Pagination
Another error is when content is spread over multiple pages. This is common on ecommerce sites that offer lots of products. You may have come across pages with navigation menus like below:

With URLs similar to these:

It is possible that Google will view these long blog posts as duplicates.
iv. URL capitalisation
Capitalised letters in the URLs are another cause of duplication problems. Examples as follows:
www.example.com/abc
www.example.com/ABC
www.example.com/Abc
This issue can easily be resolved.
v. Click and session tracking
Some websites create ‘sessions’ for reasons such as tracking customers’ behaviour. Such instances include when ecommerce sites create a session when a user is adding a product to their shopping cart. This session allows the user to continue shopping and browsing the site whilst maintaining their product(s) in the shopping cart.
A new URL will often be created when a new session has been created to allow the website to track the users’ activity. This makes it a duplication issue.
6. Use redirects correctly
There are a number of reasons why you may redirect content:
- When moving an old site to a new domain
- Directing traffic from one page to another
- Moving traffic from an expired page to an existing page
- Broken links on a page that you want to move to an alternative
There are a few different ways to redirect pages and it is advisable that you do so to avoid wasting traffic and losing your position in Google’s search results.
7. Check your internal linking
Internal links on your site can be an important factor in your site’s overall SEO. Links are not only a good navigational source for users but they also tell Google which of your pages are important.
Make it as easy as possible to help Google understand the purpose of each link. Here are the different kind of links you will find:
i. Nofollow
The purpose of a Nofollow link is to tell Google that this link should be given no SEO benefit (for example, an advertorial). Adding this code in the HTML prevents the link from receiving any benefit.
All you need to do to create a Nofollow link is to add rel=”nofollow” in the HTML code. It is recommended to Nofollow a link in the following situations:
- The link is a paid advertisement
- The links are in a comments or forum section of your site
- You’re linking to a site that may not be entirely reputable
We have seen links that have inappropriately had a Nofollow tag added to them. As a result, link value is lost.
ii. JavaScript or flash links
Links using JavaScript or Flash are not crawled in the same way as HTML links. Whilst Google does not have the ability to read most JavaScript links it is still recommended to use HTML where possible as JavaScript can still make it difficult for search engines to find your content.
8. Structured data (rich snippets)
Rich Snippers are a good way of helping your website to stand out in Google’s search results. These enable Google to show additional information, including images, as part of your listing.
Pages that use structured data, such as authorship mark up (example below) receive higher click through rates from Google than pages that don’t. Similar to listings with images – they attract approximately 20% more clicks.
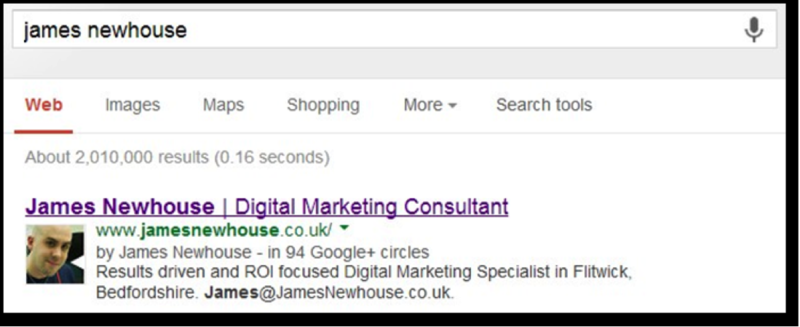
Rich Snippets can be used to mark up the following:
- Events
- People
- Places
- Local Businesses
- Products
- Offers
- Reviews
- Music
The results of adding structured data to your pages increases your visibility and generates you more traffic.
